Uge 37: Arkitekturvalg
- Kenneth H Sørensen
- Sep 12, 2025
- 5 min read

Updated: Sep 16, 2025

System, kant og indre arkitektur
Analysen dækker tre niveauer af arkitektur
Systemarkitektur: forskellen mellem monolit og microservices
Kant-arkitektur: hvordan klienter får adgang til services, f.eks via API Gateway eller BFF
Indre arkitektur (hexagonal): hvordan en service struktureres, så domænelogik adskilles fra infrastruktur og bliver lettere at teste og ændre
Jeg vil sammenligne monolit og microservices, reflektere over kant-arkitektur i forhold til vores projekt, og se på hvordan hexagonal arkitektur kan understøtte en fleksibel Ingestion Service.
Systemarkitektur
Monolit
Hvad
En applikation bygget som ét samlet program (én kodebase, ét deploy, én database)
Typisk udgangspunkt for nye applikationer - hurtig at få i gang
Udvikling, test og deployment sker samlet
Fordele
Hurtig udvikling - alt kode ét sted, nem test
Hurtig deployement - én CI/CD pipeline, én infrastruktur
Nem debug - kun ét sted at lede efter fejl
Ingen netværkslatens internt i koden - performancefordel
Ulemper
Bliver hurtigt stor og uoverskuelig
Længere release-processer - små ændringer kræver fuld deploy
Svært at skalere dele selektivt - man skalerer hele applikationen (dyrt)
Onboarding af nye udviklere kan tage lang tid

Microservices
Hvad
Bryder monolit op i mindre, selvstændige services
Hver service har én forretningsmæssig funktion
Egen infrastruktur og typisk egen database
Eks.: Netflix - separat service for søgning, streaming, anbefalinger
Fordele
Mindre, fokuserede komponenter - lettere at vedligeholde
Uafhængige releases - reducerer risiko for hele systemnedbrud
Teams kan arbejde uafhængigt - evt. med forskellig tech stack
Selektiv skalering - billigere end at skalere hele monolitten
Mulighed for hyppige releases (CI/CD på serviceniveau)
Ulemper
Sværere at køre lokalt - kræver mocks eller mange containere
Debugging i produktion - kræver god monitoring og tracing
Højere kompleksitet - flere pipelines, kontrakter, netværk, drift
Initielt dyrere infrastruktur (især for små systemer)

Kommunikation mellem microservices
Synkron (klient venter på svar)
HTTP (REST / GraphQL): Klassisk synkron request/response - simpelt, kan give latens
gRPC: Hurtigere RPC-protokol over HTTP/2 med kontrakter (protobuf) - brugt internt
Asynkron
Message broker (RabbitMQ, Kafka, AWS SQS): løs kobling og robusthed - brugt til events
Avanceret kommunikation (Reelt kun relevant i meget store microservice-miljøer)
Service mesh: Et infrastruktur-lag, der automatisk håndterer
Routing: hvilken service skal have trafikken
Service discovery: finde services uden hardkodede adresser
Reliability: retries, load balancing, fejltolerance
mTLS: kryptering og autentificering mellem services
Note: De enkelte dele kan laves andre steder end i et service mesh
Kant-arkitektur
API Gateway
Single entry point foran microservices
Håndterer
Routing
Autentifikation/autorisation (f.eks OAuth/JWT)
Rate limiting
Logging/metrics
Protokol- eller header-oversættelse
Ikke klient-specifik - kender ikke til præsentationslag eller domænelogik

Backend For Frontend (BFF)
Klientspecifikt backend-lag, ofte GraphQL
Håndterer
Aggregation af data fra flere services - returnerer kun de felter, klienten behøver
Klient-orienteret orkestrering:
Timeouts
Partial responses
Caching
I praksis en specialiseret type gateway med smallere scope (én klienttype)

I meget store systemer ser man begge mønstre.

I vores projekt er API Gateway nok.
Indre arkitektur
Hexagonal arkitektur (ports & adapters)
Formål
Adskille domænelogik fra tekniske detaljer, så kernen i systemet kan udvikles og testes uafhængigt af frameworks, databaser og eksterne systemer.
Kerneidé:
Brug porte og adapters til at skabe en klar kontrakt mellem domæne og omverden
Port: En abstrakt kontrakt som definerer, hvordan domænet taler med omgivelserne
Adapter: En konkret implementering, som forbinder en port til en teknologi
(f.eks database, REST, Kafka)
To sider
Driving side (input): Adapter starter en use case (f.eks GraphQL resolver / REST-controller)
Driven side (output): Adapter udfører noget på vegne af domænet
(f.eks database, storage, message broker)
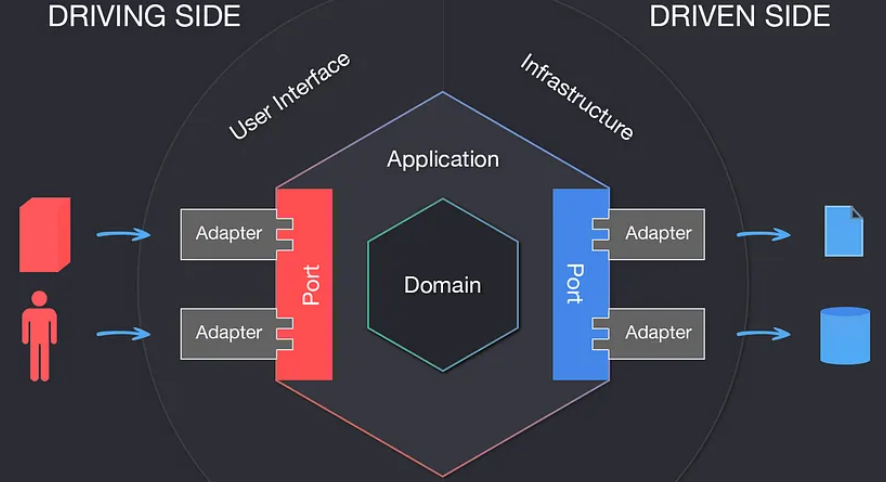
Princip
Domænelaget definerer selv sine porte. Både input og output må tilpasse sig disse kontrakter (Dependency Inversion).
Fordele
Testbarhed: Domænet kan testes uden ægte database eller broker
Fleksibilitet: Teknologier kan skiftes ud ved kun at ændre adapters
Vedligehold: Klar struktur og separation af concerns
Ulemper
Flere lag og interfaces skaber ekstra kompleksitet
Kan være overkill til små projekter, men værdifuldt når systemet vokser
Refleksion
Vi har valgt microservices, selvom det øger kompleksiteten. Det matcher Trackunits strategi og giver mig erfaring med moderne principper.
GraphQL er ikke nødvendigt for projektet, men en god læringsmulighed. Et smalt schema balancerer læring og behov.
Hexagonal arkitektur tydeliggør separation of concerns og gør test og udskiftning af teknologier enklere, især i Ingestion Service med storage, database og events.
Kant-arkitektur ift API-design
Jeg overvejede om Ingestion Service skulle tilbyde både REST og GraphQL (BFF).
Men da en teammate ser på API-gateway, ville det være overkill. Jeg har derfor valgt GraphQL som primær kontrakt - primært for læring.
REST (kendt for mig)
POST /uploads/request-url - mobilappen beder om en pre-signed URL til upload
POST /uploads/{id}/confirm - mobilappen bekræfter, at filen er lagt i storage
POST /uploads/{id}/finalize-processing - Result Service melder billede færdigbehandlet
(evt) GET /uploads/{id} - status kan hentes, hvis der er behov for det
GraphQL (nyt for mig)
mutations
mutation requestUploadUrl(mimeType, size) { uploadId, url, expiresAt }
mutation confirmUpload(id) { id, status }
mutation finalizeProcessing(id) { id, status }
query
query upload(id) { id, status }
Intern kommunikation
Jeg vil også gerne lære om message brokers for asynkron kommunikation, og Trackunit benytter selv Kafka, derfor har vi valgt at inkorporere det i projektet.
Kafka
Events publiceres af Ingestion Service, så andre services kan reagere asynkront (nyt for mig)
uploads.completed (efter confirm) - AI-service reagerer
uploads.finalized (efter finalizeProcessing) - markerer at hele kæden er afsluttet
Payload:
mindst uploadId
evt. checksum, størrelse, tidspunkt
Hexagonal arkitektur i projektet
Jeg forstår bedre hvordan hexagonal arkitektur understøtter separation of concerns, encapsulation og SOLID. Det giver et bedre billede af, hvordan testbarhed og fleksibilitet kan opnås
(f.eks ved at udskifte eksterne systemer uden at ændre domænelogikken).
Struktur i Ingestion Service
Driving side (input) GraphQL schema → Resolver (adapter) → Port (interface) → App Service App Service → output-porte Driven side (output)
|
Elementer
Resolver: tynd oversætter, ingen forretningslogik
Driving port: kontrakt ind til domænet (én use case = én metode)
Application Service: implementerer driving port og orkestrerer use case
Driven ports: kontrakter ud af domænet (storage, DB, events)
Adapters: konkrete teknologier bag driven ports
Konklusion
I uge 37 har jeg arbejdet med at forstå arkitekturvalg på system-, kant- og indre niveau og udarbejdet et High Level Design (HLD) for Ingestion Service. Det giver mig et solidt udgangspunkt til at gå videre med Low Level Design i næste uge
Videre plan
Udarbejde
LLD
Læse om
storage - dokumentation for pre-signed URLs
mere (i dybden) om GraphQL
mere (i dybden) om Message brokers og events
Ressourcer
Systemarkitektur: Microservices vs Monolit
YouTube: Monolithic vs Microservice Architecture: Which To Use and When?
Atlassian
Artikel: Microservices vs. monolithic architecture
GeeksforGeeks
Artikel: Monolithic vs. Microservices Architecture
IBM
Artikel: Monolithic architecture vs. microservices: Which works best for you?
Freecodecamp
Artikel: Microservices vs Monoliths: Benefits, Tradeoffs, and How to Choose Your App's Architecture
Kant-arkitektur: API Gateway vs Backend For Frontend (BFF)
GeeksforGeeks
Artikel: API Gateway vs Backend For Frontend (BFF)
Medium
Artikel: BFF Pattern vs Gateway Pattern
Indre arkitektur: Hexagonal arkitektur
Youtube
Medium
Artikel: Understanding Hexagonal Architecture: Ports and Adapters
Medium
Artikel: Hexagonal Architecture, there are always two sides to every story
(Evt. videre læsning)
Alistair Cockburn
Artikel: The Hexagonal (Ports & Adapters) Architecture
Youtube
Microservices: https://www.youtube.com/watch?v=rv4LlmLmVWk

